Diffusion Models:生成扩散模型
编者:郑英林
这个不是我原创的哈,是博采众长,参考了许多知乎以及论文以及博客,详细信息看参考文献
目前最近在 AI 作画这个领域 Transformer 火的一塌糊涂,AI 画画效果从 18 年的 DeepDream噩梦中惊醒过来,开始从 2022 年 OpenAI 的 DALL·E 2[2] 引来插画效果和联想效果都达到惊人效果。

但是要了解:Transformer 带来 AI + 艺术,从语言开始遇到多模态,碰撞艺术火花 这个主题,需要引申很多额外的知识点,可能跟 CV、NLP 等领域大力出奇迹的方式不同,AI + 艺术会除了遇到 Transformer 结构以外,还会涉及到 VAE、ELBO、Diffusion Model 等一系列跟数学相关的知识。
Transformer + Art 系列中,今天新挖一个 Diffusion Models 的坑,跟 VAE 一样原理很复杂,实现很粗暴。据说生成扩散模型以数学复杂闻名,似乎比 VAE、GAN 要难理解得多,是否真的如此?扩散模型能少来点数学吗?扩散模型真的做不到一个简单点的理解吗?
在本文中,我们将研究扩散模型的理论基础,然后演示如何在 PyTorch 中使用扩散模型生成图像。Let's dive in!
Diffusion Model 基本介绍
扩散模型(Diffusion Models)发表以来其实并没有收到太多的关注,因为他不像 GAN 那样简单粗暴好理解。不过最近这几年正在生成模型领域异军突起,当前最先进的两个文本生成图像——OpenAI 的 DALL·E 2 和 Google 的 Imagen,都是基于扩散模型来完成的。

如今生成扩散模型的大火,则是始于 2020 年所提出的 DDPM(Denoising Diffusion Probabilistic Model),仅在 2020 年发布的开创性论文 DDPM 就向世界展示了扩散模型的能力,在图像合成方面击败了 GAN,所以后续很多图像生成领域开始转向 DDPM 领域的研究。
看了下网上很多文章在介绍 DDPM 时,上来就引入概率转移分布,接着就是变分推断,然后极大值似然求解和引入证据下界(Evidence Lower Bound)。一堆数学记号下来,先吓跑了前几周的我(当然,从这种介绍我们可以再次看出,DDPM 实际上与 VAE 的理论关系是非常紧密),再加之人们对传统扩散模型的固有印象,所以就形成了 “需要很高深的数学知识” 的错觉。
生成模型对比
还是先横向对一下最近比较火的几个生成模型 GAN、VAE、Flow-based Models、Diffusion Models。
GAN 由一个生成器(generator)和判别器(discriminator)组成,generator 负责生成逼真数据以 “骗” 过 discriminator,而 discriminator 负责判断一个样本是真实的还是 “造” 出来的。GAN 的训练其实就是两个模型在相互学习,能不能不叫“对抗”,和谐一点。
VAE 同样希望训练一个生成模型

Diffusion Models 的灵感来自non-equilibrium thermodynamics (非平衡热力学)。理论首先定义扩散步骤的马尔可夫链,以缓慢地将随机噪声添加到数据中,然后学习逆向扩散过程以从噪声中构造所需的数据样本。与 VAE 或流模型不同,扩散模型是通过固定过程学习,并且隐空间
总的来看,Diffusion Models 领域正处于一个百花齐放的状态,这个领域有一点像 GAN 刚提出来的时候,目前的训练技术让 Diffusion Models 直接跨越了 GAN 领域调模型的阶段,直接可以用来做下游任务。
直观理解Diffusion model
生成式模型本质上是一组概率分布。如下图所示,左边是一个训练数据集,里面所有的数据都是从某个数据

但是往往
Diffusion做的是什么事呢?
我们可以将任意分布,当然也包括我们感兴趣的
从概率分布的角度来看,考虑下图瑞士卷形状的二维联合概率分布

而diffusion model其实是图上的这个逆过程
而从单个图像样本来看这个过程,扩散过程

形式化解析Diffusion model
Diffusion Models 既然叫生成模型,这意味着 Diffusion Models 用于生成与训练数据相似的数据。从根本上说,Diffusion Models 的工作原理,是通过连续添加高斯噪声来破坏训练数据,然后通过反转这个噪声过程,来学习恢复数据。
训练后,可以使用 Diffusion Models 将随机采样的噪声传入模型中,通过学习去噪过程来生成数据。也就是下面图中所对应的基本原理,不过这里面的图仍然有点粗。

更具体地说,扩散模型是一种隐变量模型(latent variable model),使用马尔可夫链(Markov Chain, MC)映射到 latent space。通过马尔可夫链,在每一个时间步 t 中逐渐将噪声添加到数据
后验概率:在贝叶斯统计中,一个随机事件或者一个不确定事件的后验概率(Posterior probability)是在考虑和给出相关证据或数据后所得到的条件概率。wiki
马尔可夫链为状态空间中经过从一个状态到另一个状态的转换的随机过程。该过程要求具备“无记忆”的性质:下一状态的概率分布只能由当前状态决定,在时间序列中它前面的事件均与之无关。这种特定类型的“无记忆性”称作马可夫性质。
Diffusion Models 分为正向的扩散过程和反向的逆扩散过程。下图为扩散过程,从
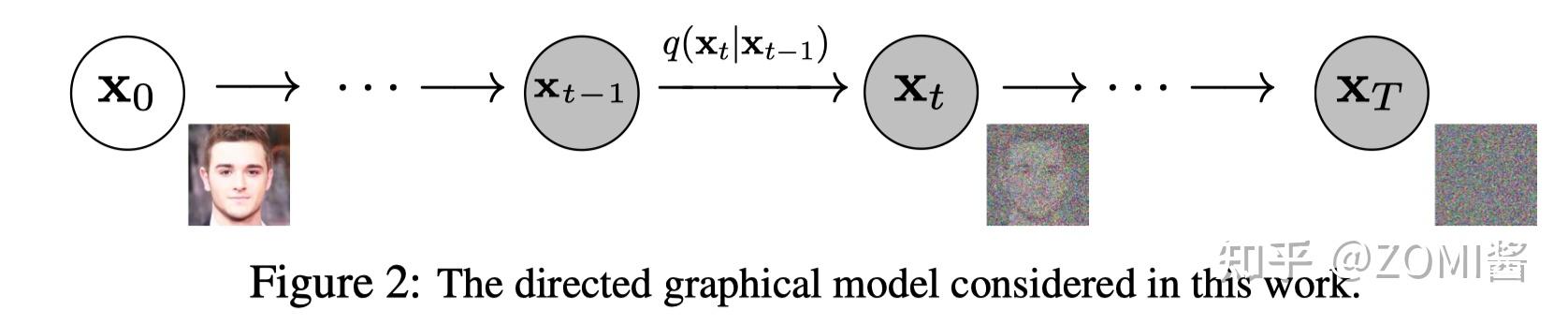
最终,从
模型训练主要集中在逆扩散过程。训练扩散模型的目标是,学习正向的反过程:即训练概率分布
读到这里就有点意思啦,Diffusion Models 跟 GAN 或者 VAE 的最大区别在于不是通过一个模型来进行生成的,而是基于马尔可夫链,通过学习噪声来生成数据。
除了生成很好玩的高质量图片之外呢,Diffusion Models 还具有许多其他好处,其中最重要的是训练过程中没有对抗了,对于 GAN 网络模型来说,对抗性训练其实是很不好调试的,因为对抗训练过程互相博弈的两个模型,对我们来说是个黑盒子。另外在训练效率方面,扩散模型还具有可扩展性和可并行性,那这里面如何加速训练过程,如何添加更多数学规则和约束,扩展到语音、文本、三维领域就很好玩了,可以出很多新文章。
详解 Diffusion Model
上面已经清晰表示了 Diffusion Models 由正向过程(或扩散过程)和反向过程(或逆扩散过程)组成,其中输入数据逐渐被噪声化,然后噪声被转换回源目标分布的样本。
接下来会是一点点数学,只能说我尽量讲得简单一点,就是个马尔可夫链 + 条件概率分布。核心在于如何使用神经网络模型,来求解马尔可夫过程的概率分布。
Diffusion 前向过程(扩散过程)
所谓前向过程,即往图片上加噪声的过程。虽然这个步骤无法做到图片生成,但是这是理解 diffusion model 以及构建训练样本 GT 至关重要的一步。
给定真实图片样本
这个过程中,随着

前向过程介绍结束前,需要讲述一下 diffusion 在实现和推导过程中要用到的两个重要特性。
特性 1:重参数(reparameterization trick)
重参数技巧在很多工作(gumbel softmax, VAE)中有所引用。如果我们要从某个分布中随机采样 (高斯分布) 一个样本,这个过程是无法反传梯度的。而这个通过高斯噪声采样得到
最通常的做法是把随机性通过一个独立的随机变量 (
上式的
特性 2:任意时刻的
在前向过程中,有一个性质非常棒,就是我们其实可以通过
首先我们令
由于两个独立高斯分布可加性,即
因此在推导的第二行,我们混合两个高斯分布得到标准差为
因此任意时刻的
实际上
一开始笔者一直不清楚为什么 Eq(1) 中diffusion 的均值每次要乘上
Diffusion 逆扩散过程
如果说前向过程 (forward) 是加噪的过程,那么逆向过程(reverse) 就是diffusion 的去噪推断过程。
如果我们能够逆转上述过程并从
然而在论文中,作者把条件概率
讲到这里我们就发现其实正向扩散和逆扩散过程都是一个骨架对吧,都是马尔可夫,然后正态分布,然后一步一步的条件概率,唯一的区别就是正向扩散里每一个条件概率的高斯分布的均值和方差都是已经确定的(依赖于
逆扩散条件概率推导
虽然我们无法得到逆转过程的概率分布
贝叶斯公式

基本的条件概率定理
乘法定理:若P(A)>0
带入贝叶斯公式
可以通过贝叶斯公式推导如下:
7-1带入了贝叶斯公式b2
7-2带入乘法公式b1,再整理一下就能得到7-3
这里是我自己推导的,只能说很艰难
7-3中巧妙地将逆向过程全部变回了前向,即
请注意,由于前向过程具有马尔可夫性质
实际上等价于 ,即公式(1),因此这里所有的概率分布我们都是已知的
7-4 分别写出其对应的高斯概率密度函数
7-5则整理成了
一般的高斯概率密度函数的指数部分应该写为
因此稍加整理我们可以得到 (6) 中的方差和均值为:
方差
关于均值的话,根据特性2的公式(2),我们得知
可以看出,在给定
通过8-1的方差以及8-3的均值,我们就得到了
训练损失
搞清楚逆扩散过程之后,现在算是搞清楚去噪推断过程。但是如何训练 Diffusion Models 以求得公式 (3) 中的均值
在 VAE 中我们学过极大似然估计的作用:对于真实的训练样本数据已知,要求模型的参数,可以使用极大似然估计。
统计学中,似然函数是一种关于统计模型参数的函数。给定输出x时,关于参数θ的似然函数L(θ|x)(在数值上)等于给定参数θ后变量X的概率:L(θ|x)=P(X=x|θ)。
Diffusion Models 通过极大似然估计,来找到逆扩散过程中马尔可夫链转换的概率分布,这就是 Diffusion Models 的训练目的。即最大化模型预测分布的对数似然,从Loss下降的角度就是最小化负对数似然:
这个过程很像VAE,即可以使用变分下界(VLB)来优化负对数似然。
我们回顾一下, KL 散度是一种不对称统计距离度量,用于衡量一个概率分布
与另外一个概率分布 的差异程度。 连续分布的 KL 散度的数学形式是: KL散度的性质:
- 非对称性:
,仅在 时等于0 由于KL散度非负,可得到
进一步对
让我们把这堆东西简化一下
接下来我们对
首先,由于前向过程
然后,
第一个
第二个分布
我们知道如果有两个分布
然后因为这两个分布的方差全是常数,和优化无关,所以其实优化目标就是两个分布均值的二范数:
这个时候我们应该也是可以用网络直接预测
因为
也就是说不用网络直接预测
然后我们把公式10带入到 公式9中
经过这样一番推导之后就是个 L2 loss。网络的输入是一张和噪声线性组合的图片,然后要估计出来这个噪声。
最后
训练过程
训练过程如图左边 Algorithm 1 Training 部分:
- 从标准高斯分布采样一个噪声
- 通过梯度下降最小化损失
- 训练到收敛为止(训练时间比较长,T 代码中设置为 1000)
测试(采样)如图右边 Algorithm 2 Sampling 部分:
- 从标准高斯分布采样一个噪声
- 从时间步 T 开始正向扩散迭代到时间步 1;
- 如果时间步不为 1,则从标准高斯分布采样一个噪声
- 根据高斯分布计算每个时间步 t 的噪声图;

快速回顾
正向 / 扩散过程
正向过程或者说是扩散过程,采用的是一个固定的 Markov chain 形式,即逐步地向图片添加高斯噪声:
在 DDPM 中,
扩散过程有一个重要的特性,我们可以直接采样任意时刻
这个解析公式使得我们可以直接获得任意程度的加噪图片,方便后续的训练。
逆向过程
逆向过程从一张随机高斯噪声图片
这个过程可以理解为,我们根据
模型训练
为了实现基于扩散模型的生成,DDPM 采用了一个 U-Net 结构的 Autoencoder 来对
此处
在 DDPM 中,逆向过程中高斯分布的方差项
总结
- Diffusion Model 通过参数化的方式表示为马尔科夫链,这意味着隐变量
- 马尔科夫链中的转变概率分布
- Diffusion Model 网络模型扩展性和鲁棒性比较强,可以选择输入和输出维度相同的网络模型,例如类似于UNet的架构,保持网络模型的输入和输出 Tensor dims 相等。
- Diffusion Model 的目的是对输入数据求极大似然函数,实际表现为通过训练来调整模型参数以最小化数据的负对数似然的变分上限
- 在概率分布转换过程中,因为通过马尔科夫假设,目标函数第4点中的变分上限都可以转变为利用 KL 散度来计算,因此避免了采用蒙特卡洛采样的方式。
参考文献
- https://zhuanlan.zhihu.com/p/549623622
- https://zhuanlan.zhihu.com/p/449284962
- https://zhuanlan.zhihu.com/p/532736667
- https://zhuanlan.zhihu.com/p/525106459
- https://lilianweng.github.io/posts/2021-07-11-diffusion-models/
- Denoising Diffusion Probabilistic Models
- Diffusion Models Beat GANs on Image Synthesis